Bagaimana jika kami memberi tahu Anda bahwa ada bagian perdagangan yang sama sekali berbeda di mana hanya elit dunia perdagangan yang tinggal? Bukan karena seorang pemula tidak bisa memasukinya; mereka kebanyakan akan kehilangan uang mereka di platform itu.
Nama aset perdagangan ini adalah Over The Counter atau OTC. Ini tidak terlalu populer di kalangan trader baru, tapi pasti mendapatkan popularitas di kalangan trader tingkat lanjut. Sebagian besar pedagang beralih ke OTC saat mereka tidak mendapatkan harga yang diinginkan untuk aset mereka melalui daftar.

Dengan demikian banyak pedagang terlihat pindah ke OTC untuk mendapatkan kesepakatan yang diinginkan.
Mungkin Anda bertanya pada diri sendiri 'Bagaimana memperdagangkan opsi biner OTC', 'Apa itu opsi biner pasar OTC', atau 'Apa arti OTC dalam opsi biner'. Kami punya jawabannya untuk Anda. Artikel ini akan membahas definisi dasar dan risiko yang terkait dengan OTC. Ini akan memungkinkan Anda untuk membuat keputusan sadar apakah Anda ingin berdagang di sini atau tidak.
Untuk mulai bereksperimen dan mempelajari dasar-dasar perdagangan, Anda dapat mendaftar di Quotex dan mulai berdagang tanpa kehilangan uang.
Definisi pasar over-the-counter:
Pasar over-the-counter atau OTC adalah tempat perdagangan terjadi secara langsung antara kedua pihak tanpa melibatkan broker pihak ketiga. Perdagangan langsung terjadi pada saham, komoditas, mata uang, atau instrumen; metodologi dan proses perdagangannya sangat berbeda dengan sistem pasar lelang tradisional.
Dealer pasar over-the-counter mengutip harga untuk menjual atau membeli aset. Harga yang dikutip tetap berada di antara kedua pihak; investor atau pembeli pasar lainnya tidak mengetahui harga transaksi di OTC. Oleh karena itu, transaksi tunduk pada jumlah peraturan yang lebih sedikit, dibandingkan dengan pasar lelang.
OTC adalah platform premium di ranah perdagangan. Dealer di platform ini tidak memiliki lokasi atau pembuat fisik. Aset yang diperdagangkan di pasar over-the-counter adalah derivatif, mata uang, obligasi, dan produk terstruktur. Poin paling menarik dari pasar over-the-counter adalah, pedagang juga dapat memperdagangkan ekuitas pada harga yang dikutip.
Di AS, pasar ini dikendalikan oleh FINRA.
Apa itu OTC Dalam Perdagangan Opsi Biner? Haruskah Anda memperdagangkannya?
Dalam paragraf yang disebutkan di atas, kita membahas apa itu OTC dalam perdagangan opsi biner? Jika Anda berdagang, itu adalah pertanyaan terbesar sepanjang masa. Jadi, dalam paragraf yang akan datang, kita akan membahas apakah seseorang harus atau tidak boleh berdagang di OTC dan opsi yang tersedia untuk berdagang.
Apa itu Opsi OTC?
Sebelum membahas apakah Anda harus atau tidak harus berdagang di konter. Anda harus berpengalaman dalam opsi biner OTC untuk membuat keputusan perdagangan yang efektif. Opsi OTC didefinisikan sebagai opsi eksotis yang diperdagangkan di OTC daripada kontrak opsi yang diperdagangkan di bursa biasa.

Opsi OTC sangat pribadi antara pembeli dan penjual. Tidak ada harga standar untuk aset; dua pihak individu yang mengutip harga. Mereka seharusnya menentukan syarat dan ketentuan mereka bersama dengan tanggal kedaluwarsa. Dalam pasar OTC, tidak ada pasar sekunder yang terlibat saat berdagang.
Memahami mekanisme trading di OTC
Mekanisme dan proses yang digunakan saat melakukan trading di pasar over-the-counter, sehingga memahami mekanisme trading di OTC sangatlah penting. Investor biasanya beralih ke OTC ketika opsi yang terdaftar tidak memenuhi kebutuhan perdagangan mereka.
Sebagian besar hanya dua pihak yang terlibat dalam OTC, tetapi pihak ketiga berbasis Pemerintah juga dapat dilibatkan untuk mengatur kesepakatan; Misalnya, FINRA mengatur pasar OTC di AS. Mempertimbangkan pembatasan pada transaksi yang terdaftar, hedger dan spekulan cenderung mengurangi syarat dan ketentuan tersebut untuk mencapai kesepakatan yang diinginkan.
Opsi OTC berbeda dalam platform dan aset karena lebih merupakan transaksi pribadi antara pembeli dan penjual. Selama pertukaran, opsi harus dibersihkan melalui clearinghouse. Dengan demikian, clearinghouse tampaknya memainkan peran sebagai perantara dalam proses perdagangan.
Ada ketentuan khusus yang ditetapkan dengan mempertimbangkan harga kesepakatan dan tanggal kedaluwarsa kesepakatan. Karena ini lebih merupakan urusan pribadi, pembeli dan penjual dapat menggunakan kombinasi harga kesepakatan dan tanggal kedaluwarsa, tergantung pada kepentingan kedua belah pihak. Beberapa syarat dan ketentuan mungkin sangat berbeda dari yang biasa di dunia perdagangan.
Karena tidak ada pengungkapan kesepakatan dari kedua belah pihak, ada kemungkinan besar bahwa bagian dari kontrak tidak dihormati oleh salah satu pihak. Dalam hal ini, mengambil tindakan hukum mungkin juga sulit. Akibatnya, para pedagang mungkin tidak menikmati tingkat perlindungan yang sama seperti yang mereka lakukan di pasar lelang normal.
Karena tidak ada platform pihak ketiga yang terlibat dalam perdagangan OTC, satu-satunya pilihan untuk menutup kesepakatan OTC adalah membuat transaksi offset. Akibatnya, efek dari perdagangan asli biasanya terlihat dibatalkan karena transaksi offset. Poin ini sangat kontras dengan norma perdagangan pasar lelang normal.
Risiko perdagangan over-the-counter
Pasar over-the-counter adalah sektor perdagangan yang sama sekali berbeda. Dengan demikian, risiko perdagangan over-the-counter juga sangat berbeda dari perdagangan online biasa. Berikut adalah beberapa risiko utama yang terlibat dalam over-the-counter jual beli:
- Pertama, sulit untuk menemukan segala bentuk informasi atau data yang dapat dipercaya tentang perusahaan. Dengan demikian meningkatkan risiko scammed selama kesepakatan.
- Kedua, sebagian besar saham atau saham dipertukarkan di pasar yang jarang diperdagangkan. Dengan demikian kemungkinan mendapatkan keuntungan yang baik lebih lanjut diturunkan.
- Ketiga, rumit bagi investor untuk berinvestasi di aset perusahaan tanpa informasi yang dapat dipercaya. Dengan demikian perusahaan biasanya tidak membeli saham dalam jumlah besar, seperti di pasar lelang biasa.
- Karena syarat dan ketentuan pengungkapan berbeda untuk OTC, ditipu juga cukup tinggi.
- Keempat, evaluasi perusahaan tidak mungkin dilakukan karena informasi publik tidak tersedia untuk perusahaan OTC.
Disini adalah tautan ke panduan video tentang perdagangan di pasar over-the-counter.

Dengan memuat video, Anda menyetujui kebijakan privasi YouTube.
Belajarlah lagi
Kelebihan dan kekurangan OTC
Pasar over-the-counter cukup kontras dengan sistem perdagangan rata-rata; Oleh karena itu, sebelum berinvestasi, Anda harus memahami dengan baik petunjuk-petunjuk dasar dari sistem tersebut. Jadi inilah kelebihan dan kekurangan OTC.
Kelebihan OTC:
- Ini adalah pilihan yang sangat bagus untuk para pedagang yang hanya aktif di akhir pekan; mereka tidak akan melewatkan penawaran bagus, tidak seperti sistem perdagangan rata-rata.
- Quotex memberi Anda berbagai aset untuk diperdagangkan, dan ini adalah salah satu opsi terbaik untuk berdagang di OTC.
- Anda juga dapat memulai trading dengan minimal $1, tidak seperti sistem trading rata-rata.
Kekurangan OTC:
- Tidak mungkin untuk melacak apakah harga aset akan naik atau turun. Anda bahkan tidak dapat memeriksa silang apakah kenaikan atau penurunan harga itu nyata; itu juga bisa menjadi penipuan besar.
- Strategi yang terlihat bekerja di pasar resmi hampir tidak terlihat berhasil di pasar yang dijual bebas.
- Hanya sekelompok kecil investor yang dapat mengatur naik atau turunnya harga. Jadi indikator teknis tidak ada gunanya di sini.
- Pasar ini bukan untuk pemula.
- Terkadang salah satu pihak mungkin mengalami kerugian karena berbagai hal mendasar karena kurangnya pengetahuan tentang aset tersebut.
7 strategi terbaik untuk perdagangan Opsi Biner OTC:
Anda harus mencatat bahwa meskipun strategi yang akan kita bahas telah dicoba dan diuji, mereka tidak terus-menerus menghasilkan keuntungan yang tinggi. SEBUAH pasar yang bergejolak tidak menjamin keuntungan bahkan dengan hak strategi opsi biner. Terkadang, Anda bahkan mungkin mengalami kerugian.
Opsi biner memberikan keuntungan yang serius, tetapi risikonya cukup besar untuk membuat para pedagang mempertanyakan batas investasi mereka. Oleh karena itu, kami menyarankan Anda untuk jaga agar investasi Anda tetap minimum dalam opsi biner.
1. Ikuti tren
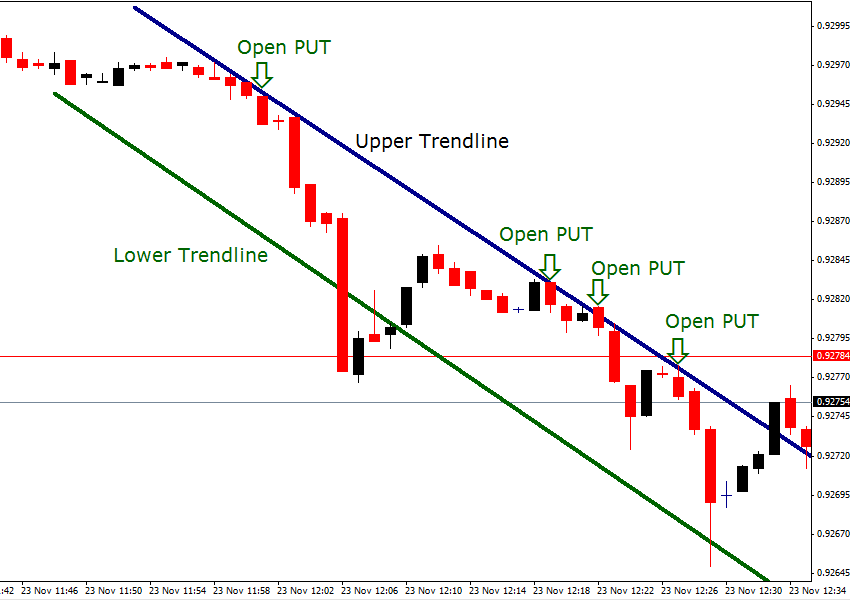
Tidak peduli di pasar apa Anda berdagang atau di saham apa Anda berinvestasi, mengikuti tren pasar adalah suatu keharusan untuk mendapatkan keuntungan. Biaya aset berubah dengan tren, dan harga aset terkait akan bereaksi sesuai.
Itu pasar opsi biner didirikan pada asumsi pedagang. Jika mereka berpikir bahwa harga suatu aset tertentu akan naik, mereka akan berinvestasi pada aset tersebut dan sebaliknya. Karena itu, tren sebagian besar mengikuti pola zigzag.
Untuk menggunakan teknik ini, pelajari grafik dengan cermat dan lihat kemana arah garis tren. Jika garisnya datar, cari aset lain untuk diperdagangkan. Jika Anda melihat garis bergerak maju, ada kemungkinan harga akan naik.
2. Ikuti beritanya
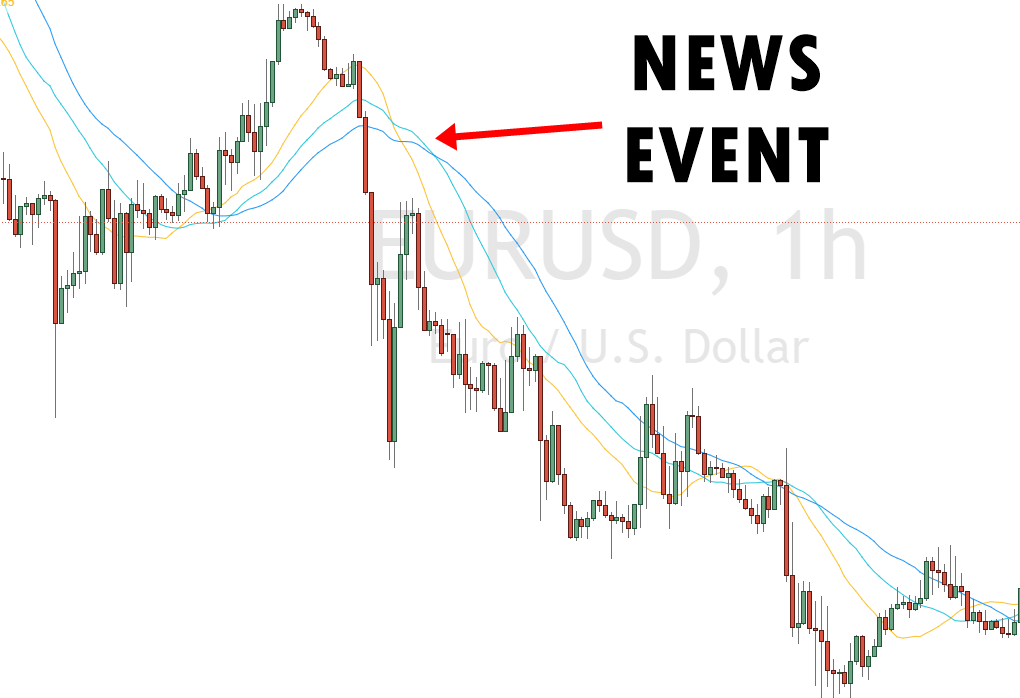
Sebagai seorang pedagang, Anda harus tahu apa yang terjadi di pasar. Ini akan membantu memprediksi bagaimana harga aset akan berfluktuasi. Anda mungkin menemukan bahwa mengikuti peristiwa berita jauh lebih mudah daripada analisis teknis tren, grafik, dll.
Anda dapat berlangganan berbagai buletin, stasiun radio, dan surat kabar yang memberikan berita keuangan. Setelah Anda memilih aset, ikuti perusahaan teknologi terkait dan tentukan kapan pengumuman akan dibuat. Jika mereka akan segera merilis produk baru, pilih opsi pembelian dan tunggu penghasilan datang setelah produk dirilis.
3. Strategi mengangkang

Itu strategi mengangkang bekerja erat dengan strategi berita. Agar strategi opsi biner OTC ini berhasil, seorang pedagang akan melakukan perdagangan mengangkang sebelum pengumuman penting yang disebutkan di bagian sebelumnya.
Nilai aset dapat meningkat dalam waktu singkat setelah pengumuman dilakukan oleh perusahaan. Dalam hal ini, Anda akan membeli opsi yang memperkirakan bahwa harga akan turun sekali lagi.
Begitu mulai turun, beli opsi lain, tapi kali ini prediksi harga akan naik lagi. Oleh karena itu, Anda menggunakan ayunan tren untuk menghasilkan uang terlepas dari fluktuasi harga opsi yang dipilih.
(Peringatan risiko: Modal Anda bisa berisiko)
4. Strategi Pinokio
Itu Strategi Pinokio melibatkan perdagangan pedagang melawan tren yang sedang berlangsung. Jika suatu aset mengikuti tren kenaikan harga, teknik Pinocchio akan menyarankan penempatan opsi yang mengharapkan harga aset tersebut turun. Anda akan mengharapkan sebaliknya jika aset mengikuti tren penurunan harga.
Periksa kandil bagan dan identifikasi apakah pasarnya kasar atau bullish pada saat perdagangan. Misalkan itu adalah pasar beruang; atur opsi panggilan Anda. Jika itu adalah optimis pasar, menempatkan opsi put.
5. Strategi pola formasi candlestick

Strategi perdagangan OTC ini mengharuskan Anda membaca bagan aset dan memastikan bagaimana harganya akan berubah seiring waktu. Itu bagian bawah candle menunjukkan harga terendah yang telah dicapai aset, dan harga historis tertinggi dikenal sebagai bagian atas lilin. Anda juga dapat melihat harga pembukaan dan penutupan perdagangan.
Anda akan melihat pola di fluktuasi harga aset saat menyelidiki sejarahnya. Ini akan menunjukkan bahwa harga naik atau turun selama waktu-waktu tertentu. Oleh karena itu, para pedagang mengandalkan informasi ini untuk menempatkan atau menempatkan opsi pada perdagangan.
(Peringatan risiko: Modal Anda bisa berisiko)
6. Analisis fundamental
Strategi OTC Biner ini membantu trader mempelajari investasi dengan lebih presisi. Ini sangat terkenal di kalangan day trader. Tujuan utamanya adalah untuk kumpulkan data tentang aset yang Anda perdagangkan. Ini akan membantu para pedagang menghasilkan keuntungan dari aset itu dengan tawaran di masa mendatang.
Misalnya, Anda tidak terbiasa dengan cara kerja aset tertentu. jika pasar bergejolak dan memiliki potensi untuk menghasilkan keuntungan, mulailah dengan menempatkan tawaran kecil pada aset tersebut. Itu akan membantu Anda dalam menemukan apakah suatu strategi menguntungkan atau tidak.
Jika Anda memperoleh keuntungan dari perdagangan kecil itu, Anda dapat menginvestasikan jumlah yang tinggi untuk keuntungan yang lebih tinggi. Tetapi jika Anda menderita kerugian, pertimbangkan mengubah strategi Anda.
7. Strategi lindung nilai

Untuk pemula, lindung nilai strategi patut dicoba. Ini sederhana untuk dieksekusi, tetapi menghasilkan keuntungan tidak selalu akurat. Trader akan menempatkan call dan put option pada aset secara bersamaan.
Strategi ini memastikan bahwa Anda akan menghasilkan uang, terlepas dari mana harga bergerak. Bahkan meskipun risiko yang terlibat lebih kecil, Anda harus mengukur risiko dan biaya kehilangan th
Kesimpulan: Apakah perdagangan OTC direkomendasikan?
Pada artikel ini, kami membahas pasar over-the-counter (OTC) cukup mendalam. Akibatnya, Anda mungkin telah memahami sisi positif dan negatif dari perdagangan di OTC. Dengan demikian Anda dapat membuat keputusan sadar tentang perdagangan di OTC.
Trading over the counter tidak disarankan untuk pemula. Biaya perdagangan minimum mungkin terdengar sangat menarik bagi pedagang baru, tetapi mereka bisa kehilangan banyak uang karena mereka tidak terbiasa dengan strategi biner OTC dasar atau pengetahuan tentang perdagangan.
Jika Anda baru dalam perdagangan, selalu mulai dengan pasar lelang. Berlatih dan bereksperimen di sana untuk mengembangkan strategi trading Anda. Anda juga bisa daftar dengan Quotex untuk belajar trading dari awal. Anda dapat [berlatih dan bereksperimen di sana tanpa kehilangan uang saat berdagang.
(Peringatan risiko: Modal Anda bisa berisiko)
Pertanyaan yang sering diajukan:
Apakah sulit untuk membeli atau menjual Opsi Biner di OTC?
Ya, terkadang sulit untuk membeli atau menjual Opsi Biner di OTC. Laju perdagangan di OTC relatif lambat, karena jumlah pembeli dan penjual terbatas.
Apakah Perdagangan OTC mempengaruhi harga aset?
Ya, perdagangan OTC pasti mempengaruhi harga aset. Nilai aset biasanya terlihat meningkat di OTC, karena permintaan pada platform ini relatif tinggi.
Strategi OTC mana untuk Opsi Biner yang dapat digunakan?
Pada dasarnya, strategi yang sama dapat digunakan untuk perdagangan OTC seperti untuk grafik biner normal. Aturan yang sama berlaku. Grafik Opsi Biner OTC akan memiliki pergerakan dan karakter yang sama seperti grafik normal. Jadi disarankan untuk tidak mengubah strategi trading.



